My Role
I'm a product manager within the Data Pipeline team, focusing on data producers' experience.
My scope is to make it easy and effective for data producers to interact with and utilize the platform to ingest and manage their data streams, so that the produced data is trustworthy and of high quality.
I work with cross-functional teams, mainly design and engineering teams, on a daily basis.
Below is an example of many projects I've provided direct design influences to.

Project: Dataset deletions tool
Enable data producers to delete unwanted datasets and manage in-progress deletions
Main users of the deletions tool = Data producers
Key results
Cutting storage costs by $600K/month across OneLake and Snowflake
Reducing support tickets by 65%
Saving dataset owners 80% of remediation time
Problem to solve
In our data ecosystem, we have accumulated tons of unwanted datasets resulted from datasets that were created by mistake, as well as datasets that are abandoned and inactive due to creation of new version of the dataset.
We have identified tens of thousands of these unwanted datasets, cluttering our data ecosystem. This creates a challenge for our data consumers to discover high quality and reliable datasets and it is time consuming for data producers to maintain so many datasets.
In addition, our support team has been getting over 300 requests related to bulk deletions a month, that's over 65% of the overall support tickets!
User research
Before engaging with the design team, I need to figure out what are the most important fields we need to display to the users. I sent out a Google survey form to the top 30 data producers to capture this.
Information that is most important to a user are:
1. Dataset name
2. Dataset version
3. Performing data steward (PDS)
4. My team
5. If a dataset contains data or not
6. The status of the deletion
In addition to the survey, I have also conducted user interviews with the top 10 data producers, and noticed the following opportunities-
1. Often times, data producers need to delete more than 1 dataset at a time
2. In addition to delete, data producers also want the ability to manage any in progress deletions
Product Intent
TL;DR: We need a deletion tool so data producers can (1) search and delete one or multiple datasets, (2) have enough information to empower them to make good decisions on what datasets to delete, and (3) manage their existing dataset deletions, enable them to know the status for each deletion
Design - v1
After setting expectations with the design team on the goal of the project. Our design team has come up with the v1 of the dataset deletion tool.
Data producers can filter, search and sort datasets they owned and act on them -
Single action: User can either delete a single dataset using the "Delete" button action, or cancel any single pending deletion using the "Keep" action button.
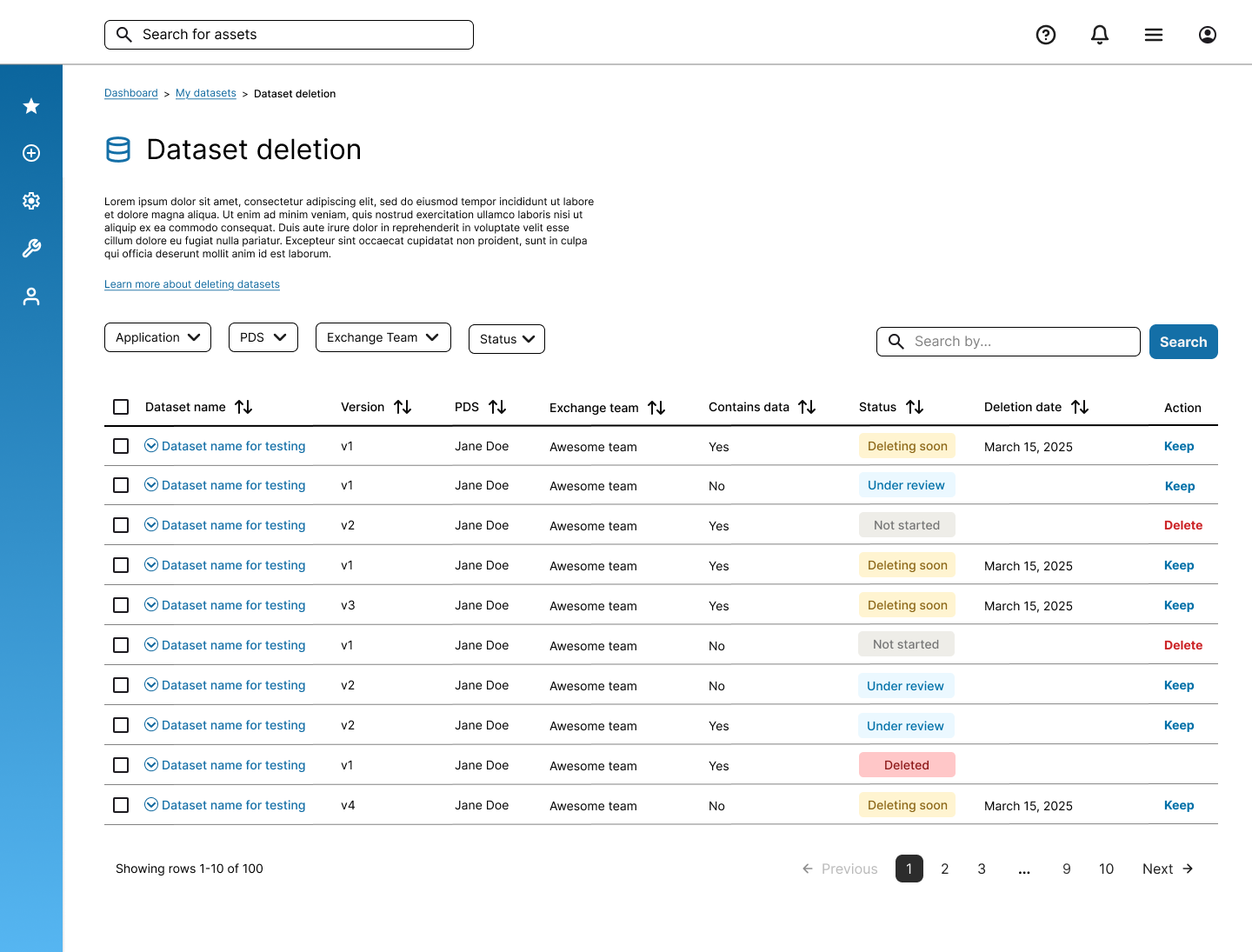
Bulk action: By selecting the checkbox, user will trigger a bulk action panel.

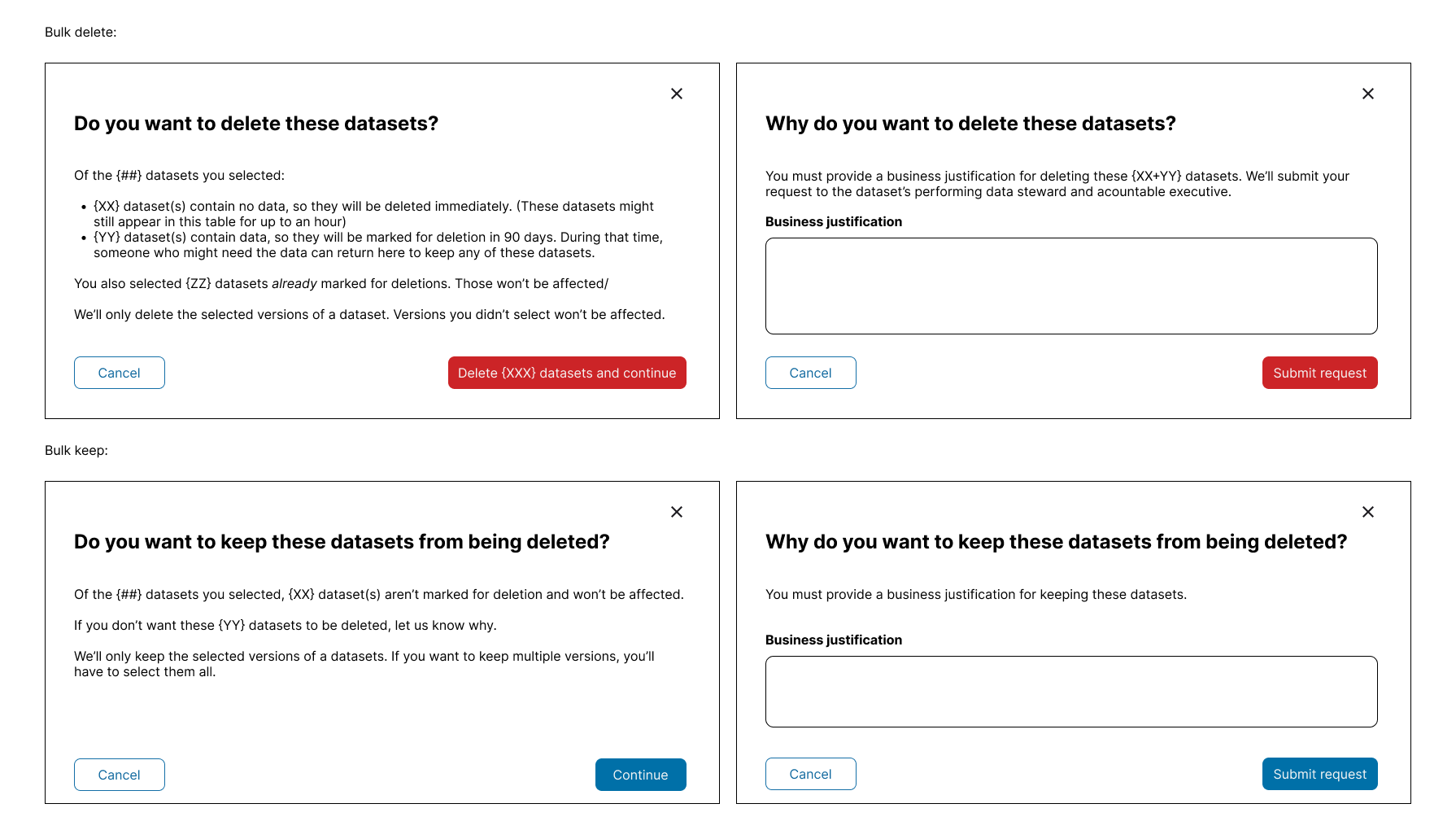
Mixed selections of 2 different types of datasets
My first reaction to this v1 design was "What happened when a user selected a mix type of datasets?"
There are 2 ways to address this -
1. Disable the bulk action until user select only one type of dataset, either to delete or to keep
Pro: Low level of effort on tech implementation
Con: This may create user frustration
2. With the help of the content team, we came up with the below modals that enable users to continue with the process
Pro: Allow users to continue with the flow without stopping them
Con: (1) Higher level of effort on tech implementation (2) Too much information for user to read
Design influences 1
The 2 main jobs to be done (JTBD) with the deletion tool are:
1. I want to delete datasets
2. I want to manage my pending deletions
Instead of keeping all datasets in one view, we can separate them into 2 views - (1) a view for all datasets that are not currently in any deletion period, and (2) a view for all datasets that will be deleting soon
Having separate views can (1) clearly define the JTBD on each tab, and (2) users will not run into a scenario where they select mixed types of datasets.
Design influences 2
From our research, we know that users often delete more than 1 dataset at a time, but what's the average of datasets they are deleting?
• User A deleted 700 datasets
• User B deleted 60 datasets
• User C is expecting to delete 345 datasets
There isn't really an average number I can use here since the number varies a lot.
My next step is to talk to my tech team. During a refinement session, I learned that there's a tech tradeoff on the number of datasets we can display within a page vs the load time, as well as the number of dataset in each bulk request vs the time to process. At the end, we concluded that we should only display 20 datasets on a page and limit up to 20 datasets in a bulk request.
If we only allow user to bulk delete up to 20 datasets, the use case for User A above will need to submit the bulk deletion request 35 times! I've read some articles in the past on how different applications handle bulk request, and one of them is to utilize a bulk uploader that will process data from a file.
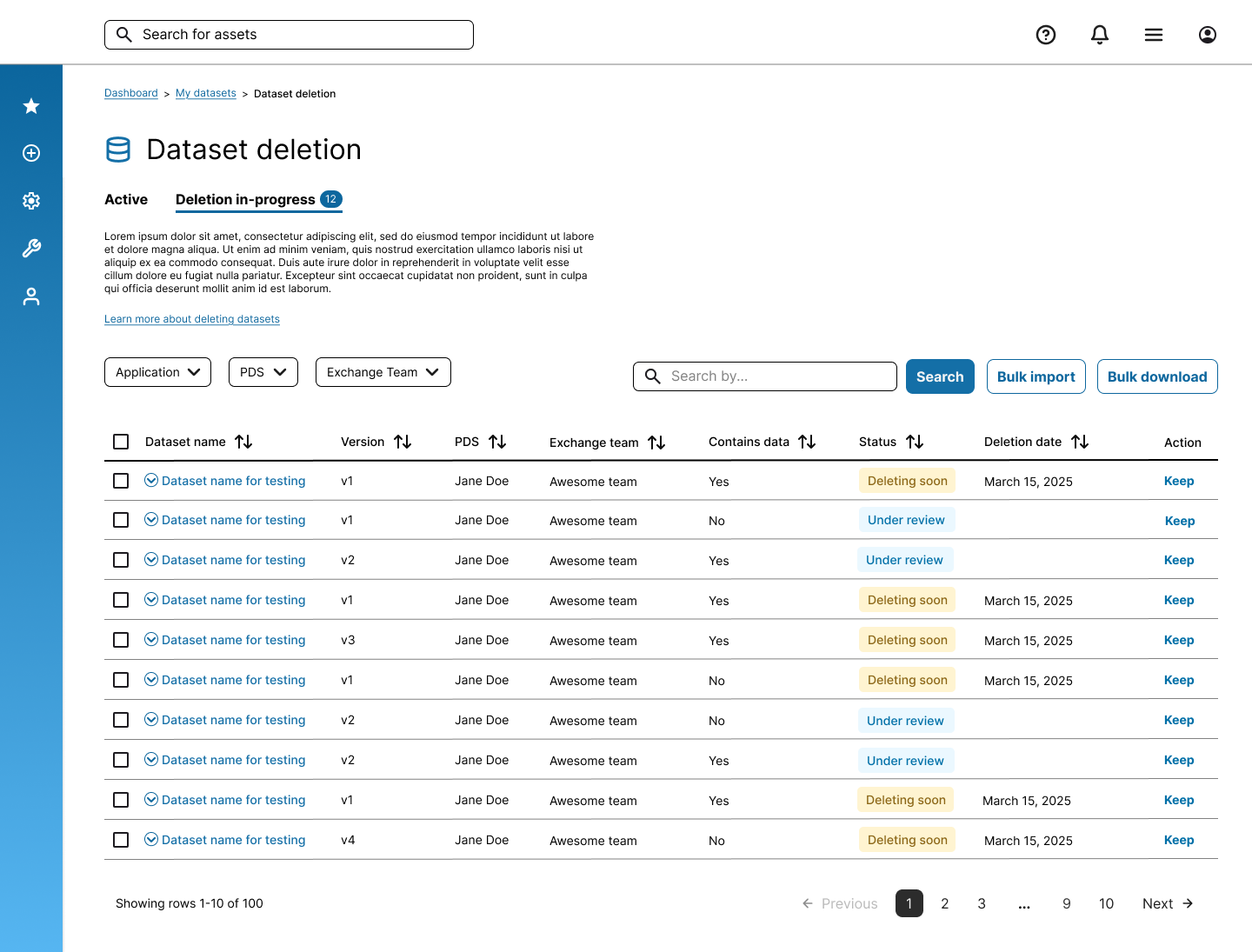
Design - v2 (final design)
Design revisions made resulted from my influences:
• Divide datasets that into 2 separate tabs:
(1) active datasets (not in any deletion process), and
(2) datasets that are in the process of deleting soon
• Added additional buttons to allow user to:
(1) download a list of datasets they owned, and
(2) upload a list of datasets to either bulk delete or bulk keep
Another benefit of having separate tab is the removal of the unnecessary fields such as "status" and "deletion data" within the "active" tab, since these two fields do not apply to datasets that are not yet started the deletion process.

User feedbacks
Before we decide which version of the design we should implement, I conducted another round of interviews with the top 10 power users as well as in a forum with a group of 50 managing data stewards, and here's the result:
95% of the users prefer version 2 of the design
"I like the 2 tabs version because I can easily see a list of datasets that can be deleted an a list of datasets that already started the deletion process"
